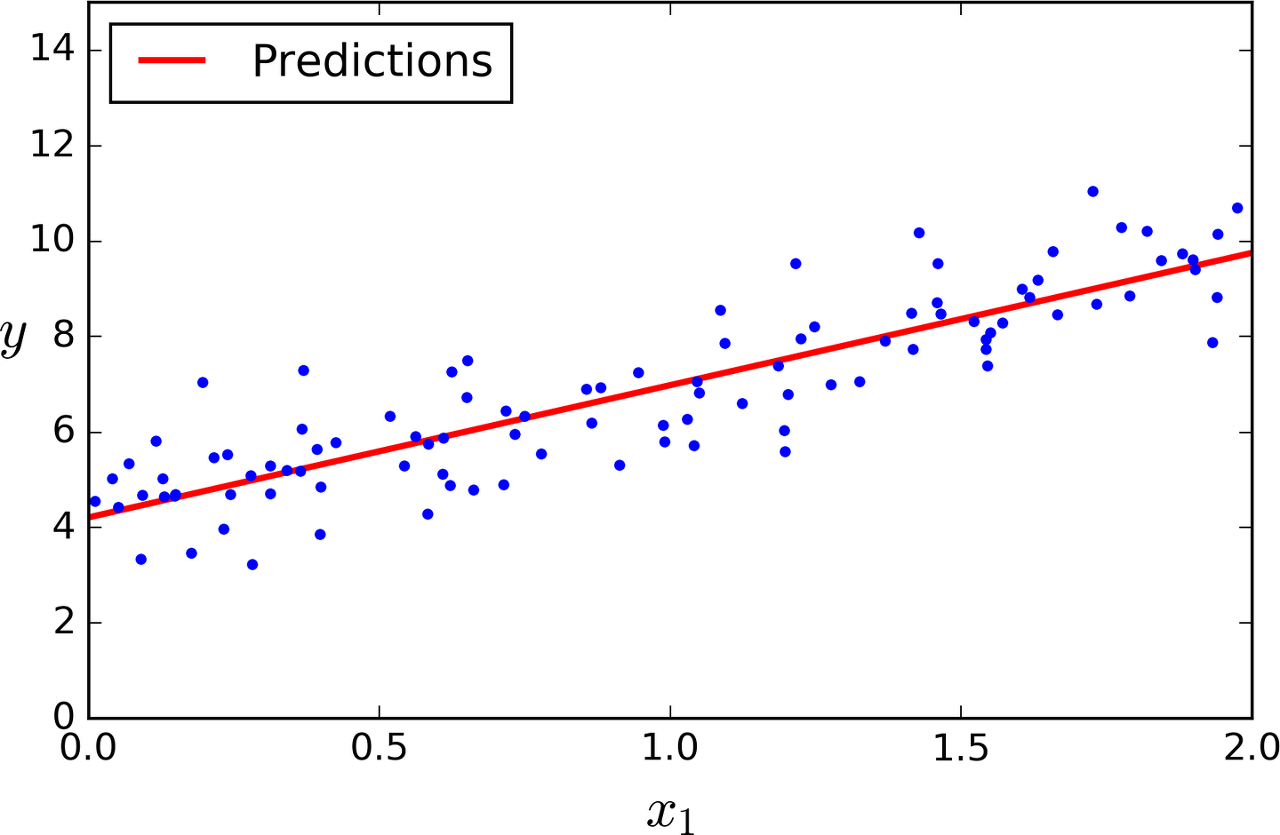
목차 들어가며 선형회귀의 정의 파라미터 계산 정규방정식 정규방정식의 장단점 경사하강법 정의 학습률로인한 장단점 배치 경사 하강법 확률적 경사 하강법 미니배치 경사 하강법 들어가며 이번 글에서는 머신러닝의 모델 중 하나인 선형회귀의 정의와 모델의 파라미터를 최적화하는 방법들에 대해서 설명하도록 하겠습니다. 선형회귀의 정의 선형회귀란 주어진 데이터( x는 샘플, y는 예측값)들을 사용해서 샘플과 예측값과의 관계를 직선으로 표현하는것을 의미합니다. 직선의 방정식을 구하기 위해서는 하나의 샘플에서 각 특성에 곱할 기울기들과 편향이 필요합니다. 우리는 주어진 데이터들을 통해서 해석적으로 또는 경사하강법같은 계산을 통해서 파라미터(기울기, 편향)을 파악할 수 있습니다. 파라미터 계산 1. 정규방정식 선형회귀는 최적..