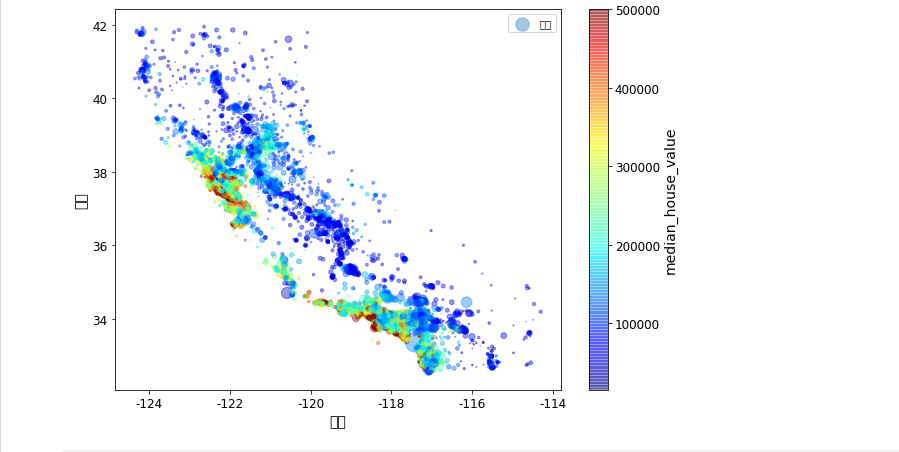
들어가며 지난 글에서 데이터 스누핑이 일어나지 않기 위해 테스트 데이터를 추출하는과정을 진행했습니다. 이번에는 모델을 구상하기위해서 훈련 데이터만을 가지고 데이터에 대해 깊게 탐색해보도록 합시다. 훈련 데이터만을 가지고 탐색하는 것 또한 데이터 스누핑을 피하기 위해서 입니다. 만약 테스트 세트로 탐색을 할 경우 개발자는 데이터에 최적화된 알고리즘을 적용하려고 하므로 과대적합이 발생할 수 있기 때문입니다. 3.1 지리적 데이터의 시각화 경도와 위도에 대한 정보를 바탕으로 데이터를 산점도로 표현하여 지리적 데이터를 시각화 해봅시다. https://colab.research.google.com/drive/1wWaPMCEb3ewf3CNKIeu262vQaCG36apw#scrollTo=aroTxF3Ja5mD&lin..