신경망의 구조
신경망은 앞서 언급했던 퍼셉트론(여러 개의 입력을 계산하여 하나의 결과값을 출력하는 객체)과 공통점이 많습니다. 이번에는 신경망과 퍼셉트론의 차이점을 주로 설명하여 신경망에 대해서 설명하겠습니다.

신경망은 여러개의 퍼셉트론을 연결하여 입력층, 은닉층 그리고 출력층을 제작한 것입니다.
입력층은 우리가 분석하고자 하는 데이터를 입력할 때 사용되는 층입니다. 그리고 신경망이 데이터를 분석할 때 하나 이상의 은닉층에서는 매 번 가중치를 곱하고 결과값을 다음 은닉층에 전달하는 과정이 일어납니다. 이러한 일련의 과정을 거쳐 출력층에서 우리가 원하는 결과값이 출력되는 것입니다.
우리의 몸으로 비유를 하자면 눈으로 사물을 인식하는 것이 입력층이고 시각신호가 뇌에서 처리되는 것이 은닉층 그리고 은닉층을 통해서 우리는 어떤 사물인지 인지하는 결과가 출력층인 것입니다.

활성화 함수
활성화 함수란 입력신호의 총합을 어떤 출력신호로 변화시킬지 정하는 함수입니다.

퍼셉트론에서는 데이터의 총합이 임계값을 넘으면 1 그렇지 않으면 0을 출력하는 단순한 구조였지만 신경망에서는 인공뉴런들이 데이터의 총합을 독특한 방식으로 출력합니다.
1. 시그모이드 함수

# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.arange(-5.0, 5.0, 0.1)
Y = sigmoid(X)
plt.plot(X, Y)
plt.ylim(-0.1, 1.1)
plt.show()
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.arange(-5.0, 5.0, 0.1)
Y = sigmoid(X)
plt.plot(X, Y)
plt.ylim(-0.1, 1.1)
plt.show()
시그모이드 함수는 사용하는 뉴런은 각각의 데이터와 가중치의 총합을 시그모이드 함수로 계산한 결과값을 다음 층에 전달합니다. 입력값이 0보다 더 큰 경우 1에 가까운 결과값을 출력하고 0보다 작을 수록 0에 가까운 결과값을 출력하는 것이 특징입니다.
초기에는 자주 logistic classification 신경망에 사용되었지만 여러가지 단점들이 부각되고 ReLU함수의 등장으로 최근에는 사용하지 않게 되었습니다.
2. 계단함수

# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return np.array(x > 0, dtype=np.int);
x=np.arange(-5,5,0.1);
y=function(x);
plt.plot(x,y);
plt.show();계단 함수는 0을 기준으로 0보다 크면 1, 0보다 작으면 0을 출력하는 함수 입니다.
이 함수는 입력값에 비해서 출력값이 0을 기준으로 극단적으로 출력하는 함수 이기 때문에 신호처리 분야에서 자주 사용되는 함수 입니다.
3. ReLU 함수
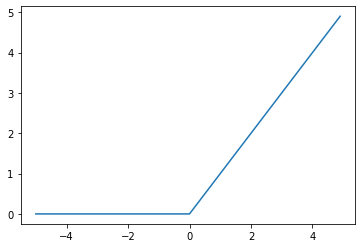
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
def function(x):
return np.maximum(0,x);
x=np.arange(-5,5,0.1);
y=function(x);
plt.plot(x,y);
plt.show();ReLU(Recrified Linear Unit, 정류된 선형 함수)는 0이하의 입력값은 모두 0으로 0이상의 출력값은 그대로 출력하는 함수입니다. 시그모이드 함수로 인해 발생하는 문제(vanishing gradient)를 해결하기 위해 사용된 함수로써 현재 가장 많이 사용되는 함수입니다.
** 활성화 함수의 특징 : 활성화 함수는 여러가지가 존재 할 수 있지만 반드시 비선형 함수여야 합니다. 선형함수인 경우 여러개의 층을연결하여 계속 계산하는 것은 한 번 계산하는 것과 동일하기에 의미가 없기 때문입니다.**
'Machine Learning' 카테고리의 다른 글
| 신경망 학습 - (4 - 1) 확률적 경사 하강법, SGD( Stochastic Gradient Descent ) (0) | 2020.01.21 |
|---|---|
| 신경망 학습 - (3) 오차 역전파(Backpropagation) (0) | 2020.01.20 |
| 신경망 학습 - (2) 미니배치 학습, 기울기 그리고 신경망 학습 (0) | 2020.01.19 |
| 신경망 학습 - (1) 손실함수( MSE, CEE) (0) | 2020.01.19 |
| Deep Learning from Scratch - 1 (Chapter 1 ~ 4) 신경망 (0) | 2019.05.18 |