목차
- 들어가며
- 선형회귀의 정의
- 파라미터 계산
- 정규방정식
- 정규방정식의 장단점
- 경사하강법
- 정의
- 학습률로인한 장단점
- 배치 경사 하강법
- 확률적 경사 하강법
- 미니배치 경사 하강법
- 정규방정식
들어가며
이번 글에서는 머신러닝의 모델 중 하나인 선형회귀의 정의와 모델의 파라미터를 최적화하는 방법들에 대해서 설명하도록 하겠습니다.
선형회귀의 정의

선형회귀란 주어진 데이터( x는 샘플, y는 예측값)들을 사용해서 샘플과 예측값과의 관계를 직선으로 표현하는것을 의미합니다. 직선의 방정식을 구하기 위해서는 하나의 샘플에서 각 특성에 곱할 기울기들과 편향이 필요합니다. 우리는 주어진 데이터들을 통해서 해석적으로 또는 경사하강법같은 계산을 통해서 파라미터(기울기, 편향)을 파악할 수 있습니다.
파라미터 계산
1. 정규방정식
선형회귀는 최적화된 파라미터를 공식을 통해서 해석적으로 구할 수 있습니다. 이를 정규방정식이라고 부릅니다.

파이썬으로 이를 구현해보겠습니다.
1.1. 선형으로 보이는 데이터를 생성합니다.

Google Colaboratory
colab.research.google.com
1.2. 정규방정식으로 파라미터를 계산합니다.
[4,3]의 결괏값을 원했지만 가우시안 노이즈 때문에 살짝 오차가 존재합니다.

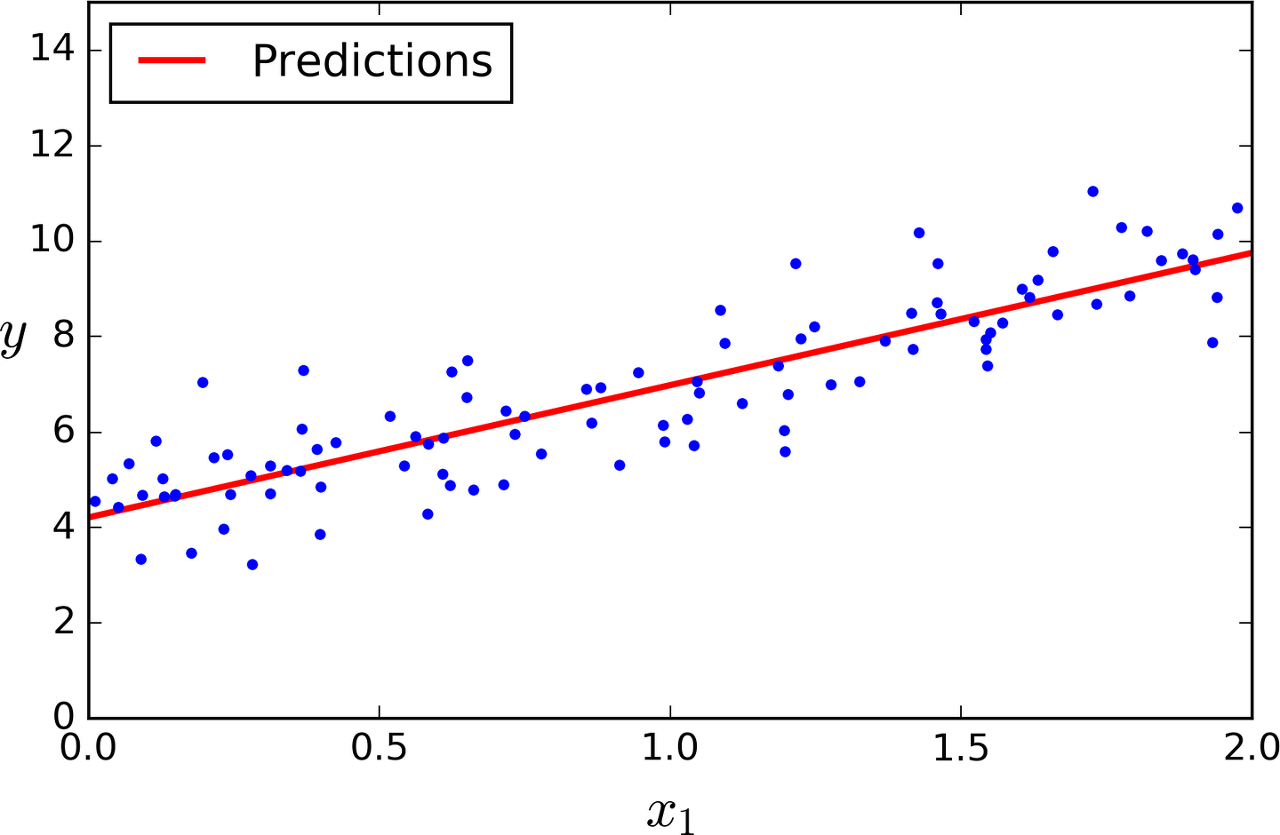
1.3. 모델의 예측을 그래프에 나타내보겠습니다.

1.4. 동일한 작업을 사이킷런 라이브러리를 통해 작업합니다.

정규방정식의 장단점
우선 정규방정식의 장점은 선형회귀에 사용되는 여러방법중 가장 정확하게 파라미터를 계산할 수 있다는 것입니다. 이는 해석적으로 계산하기에 당연한 결과입니다.
단점은 이를 계산하기 위한 컴퓨팅자원의 한계입니다.
1. 정규방정식으로 계산을 하기 위해서는 램에 모든 샘플들을 올린 다음 계산할 필요가 있습니다. 만약 샘플의 크기가 매우 크기에 램이 부족하다면 이런 방법은 어려움이 있습니다.
2. 시간복잡도의 기하학적 증가
정규방정식의 시간복잡도는 O(n^2.4) ~ O(n^3) [ n : 행렬의 크기 ] 정도로 샘플의 행렬이 증가할 경우 기하학적으로 계산시간이 증가하게 됩니다.
따라서 소규모의 샘플 계산인 경우 정규방정식을 사용하는 것이 좋지만 자원의 한계에 부딪힐 정도로 샘플의 수가 많은 경우 다른 방법을 사용하는 것이 좋습니다.
2. 경사하강법( Gradinet Descent)
2.1.정의
경사하강법은 비용함수를 최소화하기 위해 비용함수의 편도함수를 이용해서 파라미터를 조정하는것입니다.
위 정의를 하나씩 풀어 봅시다. 우선 비용함수는 쉽게 말해서 예측값과 실제 정답의 차이를 의미하는 함수를 의미합니다. 이 함수는 여러종류가 있지만 여기서는 MSE(평균 제곱 오차,Mean Squared Error)로 다루어보도록 하겠습니다.

위 식은 각 샘플의 예측값과 정답의 차이를 제곱하여 평균을 나타내는 것을 의미합니다.
즉 비용함수(손실함수)가 낮을 수록 예측이 정확하다는 것을 의미합니다. 비용함수를 낮추기 위해서는 함수의 편도함수를 구하여 기울기의 방향을 파악하고 비용함수가 낮아지는 방향으로 파라미터를 수정하면됩니다.

좋습니다. 비용함수의 편도함수로 파라미터를 조정할 방향을 알아보았습니다. 이번에는 방향을 알았으니 얼마나 움직여야할지 크기(학습률)에 대해서 알아보겠습니다.
2.2학습률로 인한 장단점
우선 학습률이 작을 때 입니다.

학습률이 작을 경우 매번 스텝마다 매우 작게 움직이기 때문에 파라미터가 최적화되기에 오랜시간이 소요됩니다.
이번에는 학습률이 평균보다 클 때입니다.

학습률이 매우 큰 경우 비용함수의 최소점에 수렴하지 못하고 지그재그로 이동하는 모습을 볼 수 있습니다.
경사하강법의 문제점
학습률에 상관없이 경사하강법에는 비용함수가 볼록,오목함수가 아닌 경우에 전역 극소값이 아니라 지역 극솟값에만 머무르게 되어 학습이 정체되는 현상이 발생할 수 있습니다. 이러한 경우는 모멘텀 기반 방식으로 해결할 수 있습니다.

2.3 배치 경사 하강법
배치 경사 하강법은 경사 하강법의 가장 일반적인 구조로 한번 비용함수의 기울기를 계산할 때마다 모든 샘플을 사용하는것을 의미합니다. 이를 구현하기 위해서 모든 샘플에 대한 MSE의 편도함수를 우선 구해봅시다.

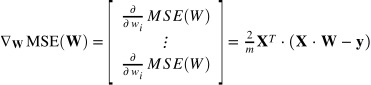
편도함수는 해석적으로 풀이할 경우 두 번째 공식을 사용하여 구할 수 있습니다. ( 배치 경사하강법 이므로 모든 샘플 데이터를 사용합니다.)
이를 코드로 구현해봅시다.
eta = 0.1 # 학습률
n_iterations = 1000 #반복횟수
m = 100 # 샘플의 갯수
weight = np.random.randn(2, 1) # 초기 랜덤 파라미터 설정
for step in range(n_iterations):
gradients = 2/m * X_b.T.dot(X_b.dot(weight) - y) #기울기 계산
weight = weight - eta * gradients # 학습률의 크기만큼 기울기 방향으로 이동
#파라미터의 변화 파악
if (step+1) % 200 == 0:
print('Step :{:04d}, weight = \n {}'.format(step+1, weight))
print('최종 결과값 : \n{}'.format(weight))
약 1000번의 반복을 통해서 정규방정식으로 구한 파라미터의 최적화에 근사한 값을 도출했습니다. 반복횟수를 조절해서 시간의 소요를 조절할 수 있지만 한번의 계산에 모든 샘플을 사용하기에 이 또한 정규방정식처럼 램 용량을 초과할 수 있습니다. 이번에는 이를 해결하기 위해 확률적 경사 하강법에 대해서 알아보도록 하겠습니다.
2.4 확률적 경사하강법
확률적 경사 하강법(Stochastic Gradient Descent)은 매 스텝에서 랜덤하게 하나의 데이터(샘플)을 선택해 Gradient Descent(GD)를 계산하는 방식입니다. 이 방식은 배치 경사하강법에 비해 불안정하게 최적값으로 수렴하지만 시간과 사용되는 램용량을 단축할 수 있습니다.
불안정하게 수렴할 경우 local minimum에서 탈출할 가능성이 있지만 반대로 global minimum에는 도착하지 못할 가능성이 있습니다. 이를 해결하기 위해서 SGD에서는 학습률을 점진적으로 감소시키는 Learning Rate Decay(learning rate schedule)기법을 사용합니다.
Learning Rate Decay기법
학습을 시작할 떄는 학습률을 크게 설정하고 점진적으로 이를 줄여 전역 최솟값에 도달하는 방식입니다.
이를 코드로 구현해보도록 하겠습니다.
n_epochs = 50
t0, t1 = 5, 50
def learning_schedule(t):
return t0 / (t + t1)
weight = np.random.randn(2, 1) # random init
for epoch in range(n_epochs):
for i in range(m):
if epoch == 0 and i < 20:
y_predict = X_new_b.dot(weight)
style = 'b-' if i > 0 else 'r--'
plt.plot(X_new, y_predict, style)
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(weight) - yi)
eta - learning_schedule(epoch * m + i)
weight = weight - eta * gradients
weight_path_sgd.append(weight)
if (epoch+1) % 10 == 0:
print('Epoch :{:03d}, weight = \n {}'.format(epoch+1, weight))
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
에폭마다 학습률을 점진적으로 낮추면서 진행한 결과 파라미터가 최적값으로 수렴하는 것을 확인 할 수 있습니다.
SGD를 이용한 Regressor는 사이킷런에서 모듈을 지원하므로 이를 사용해 간단하게 계산할 수 있습니다.
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=50, penalty=None, eta0=0.1, random_state=42)
sgd_reg.fit(X, y.ravel())
print(sgd_reg.intercept_, sgd_reg.coef_)2.5 미니배치 경사하강법
미니배치 경사 하강법(Mini-batch Gradient Descent)은 각 스텝에서 전체 Train Set을 미니배치(mini-batch), 즉 작은 데이터셋을 추출한 뒤 Gradient를 계산하는 방법입니다.
미니배치 경사 하강법은 SGD에 비해 덜 불규칙하게 감소하지만, local minimum에 빠질 확률은 높은 경우가 있습니다.
최종비교

위에서 설명햇듯이 3가지 방식을 비교해보면 배치경사하강법은 매번 파라미터 갱신 때마다 전체 샘플을 계산하므로 안정적으로 수렴하는 반면 SGD는 하나씩만 사용하기에 불안정한 모습을 볼 수 있습니다. 그리고 갱신때마다 일부 샘플만을 사용하는 미니배치의 경우에는 SGD보다는 좀 더 안정적으로 수렴하는 모습을 볼 수 있습니다.
'Machine Learning' 카테고리의 다른 글
| 머신러닝 모델 - 학습곡선(다항 회귀의 차원 설정) (0) | 2020.04.16 |
|---|---|
| 머신러닝 모델 - 2. 다항회귀(Polynomial Regression) (0) | 2020.04.16 |
| 머신러닝 프로젝트 - 10. 최상의 모델과 오차 분석 (1) | 2020.03.10 |
| 머신러닝 프로젝트 - 9. 모델 세부 튜닝(그리드 탐색, 랜덤 탐색) (0) | 2020.03.10 |
| 머신러닝 프로젝트 - 8. 교차검증( K-fold cross-validation) (0) | 2020.03.09 |