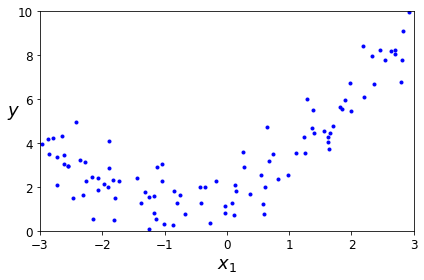
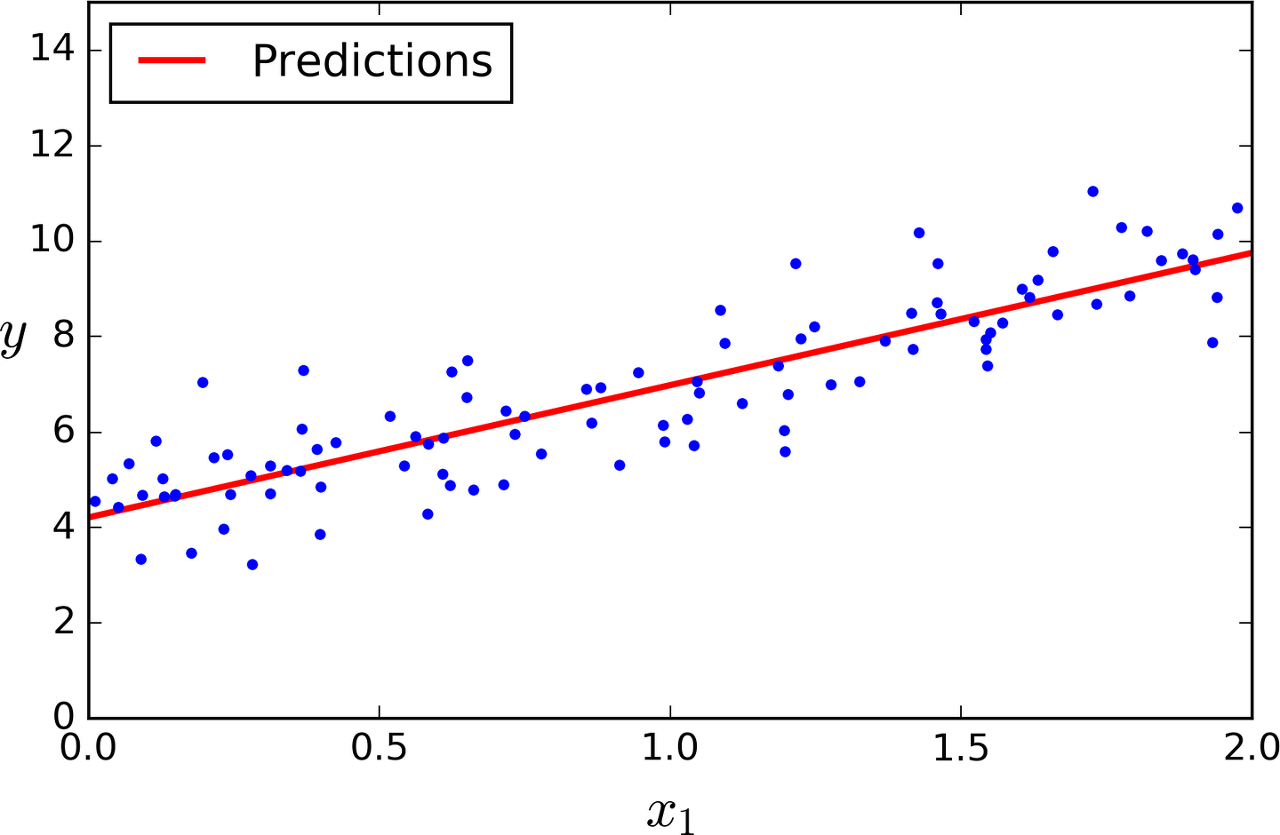
들어가며 이전 글에서는 데이터 간의 비선형관계를 구하기 위한 다항회귀에 대해서 알아보았습니다. 이제 데이터에 적합한 차수(degree( 2차, 3차 등 ))를 어떻게 구할지 고민해야합니다. 이번에는 학습곡선을 통해서 다항회귀를 할때 차수를 적절하게 구하는 방법에 대해서 알아보도록 하겠습니다. 목차 1. 차수의 중요성 2. 학습곡선을 통한 적합성파악 3. 모델의 일반화 오차 1. 차수의 중요성 위 그림은 이전 글(다항회귀)에서 사용한 2차곡선형의 데이터 샘플입니다. 만약 Degree를 300이나 1로 지정할 경우 어떻게 되는지 한번 알아보도록 하겠습니다. from sklearn.preprocessing import StandardScaler from sklearn.pipeline import Pipelin..